29 Septembre 2023
NoHasba: Persistence JSON, relationnelle, ou les deux...
NoHasba est un projet personnel développé pendant ma formation en développement web et mobile. Il a été l'occasion d'explorer diverses technologies, notamment une base de données relationnelle et l'inversion de dépendance. L'application permet de gérer des groupes de dépenses, même si elle n'est pas abouti sur le plan de l'interface utilisateur.
J'ai introduit l'inversion de dépendance en utilisant une interface "Trigroup" avec des implémentations spécifiques pour le stockage en JSON ou en SQL, offrant une flexibilité accrue et une modularité au projet. Cela a permis d'améliorer la maintenabilité et la qualité du code tout en préparant le terrain pour de futures évolutions.
j'ai choisi MySQL pour la base de données, ce qui a nécessité de créer des tables interconnectées pour stocker les informations sur les groupes, les utilisateurs et les dépenses. J'ai également mis en place des migrations SQL pour gérer les évolutions de la structure de la base de données.
Enfin, une partie essentielle du projet est l'algorithme de calcul des dettes entre les membres d'un groupe, expliqué en détail.
NoHasba est un projet que j'ai développé pendant ma formation développeur web•web mobile sur mon temps libre. Le
but était de découvrir par la pratique quelques technologies, concepts.
Avant ma première ligne de code, je voulais expérimenter avec une base de données relationnelle et l'inversion
de dépendance. J'avais choisi de copier le métier de
tricount
pour avoir un challenge en algorithme.
Demo
Mais enfaite, il sert à quoi le site?
En l'état, il ne sert à rien. J'ai très peu travailler sur le front mais j'ai tout de même quelques screenshot pour vous.
Créer un groupe
Voir les dépenses du groupe

Comment régler les dettes du groupe
La création des dépenses et des utilisateurs d'un groupe se fait à l'aide de requêtes http (postman, insomnia, curl)
BDD Relationnelle
N'ayant utilisé que mongoDB avant le développement de NoHasba, j'ai fait beaucoup de veille avant de commencer.
Comment choisir, ou comment m'y prendre pour initialisé ma base de données ?
Après quelques temps à regarder des vidéos et lire des articles j'ai décidé d'utilisé MySQL, car les besoins de
mon
applications étaient minime et la prise en main pour un premier projet m'a semblé plus facile.
Et interdiction d'utilisé un ORM pour écrire mes propres requête sql.
J'avais déjà une base de données en JSON, je n'ai donc pas eu trop de mal à identifier mes tables.(plus de détails dans la partie "Inversion de Dépendance")
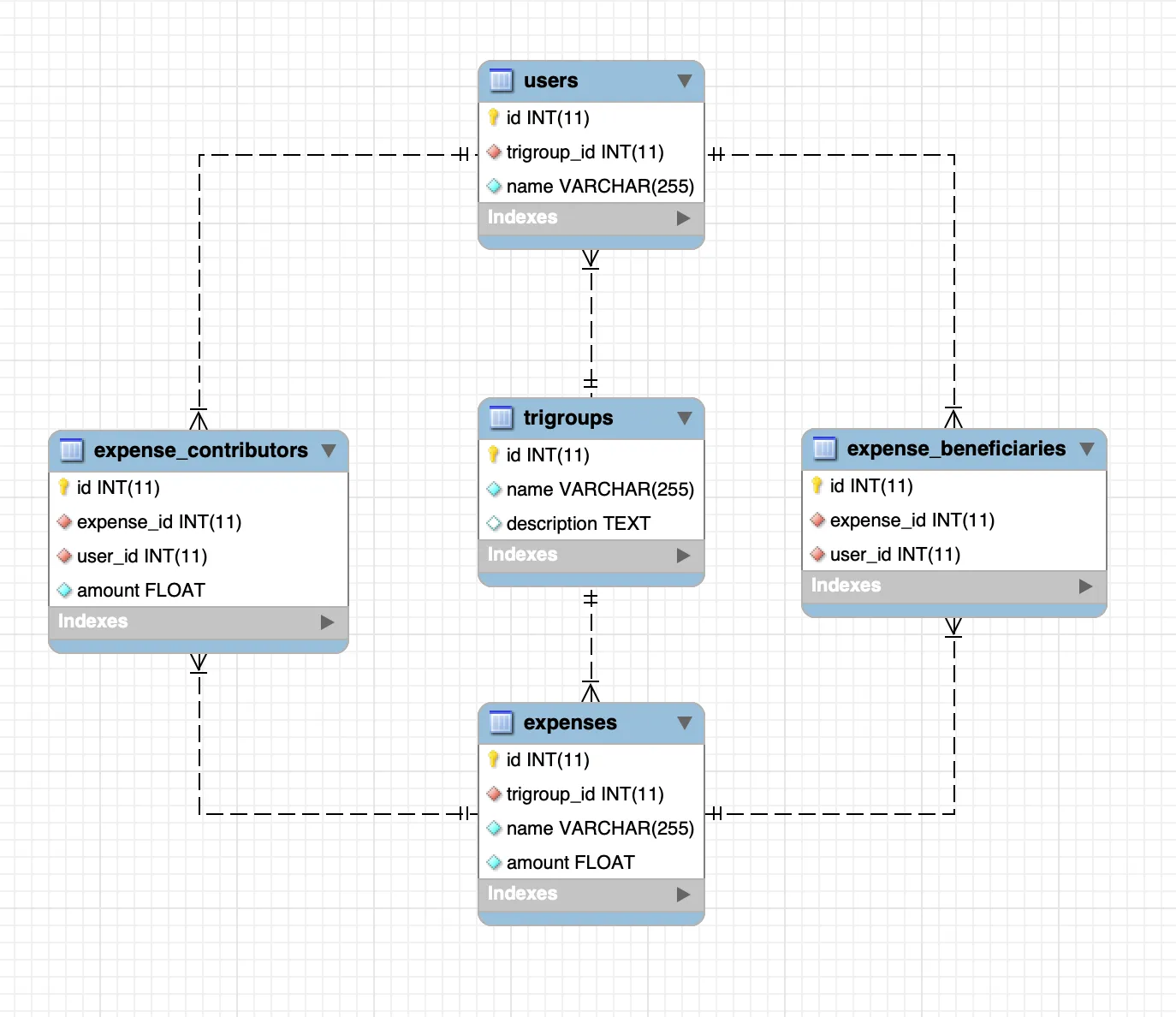
La base de données est composée de plusieurs tables interconnectées, chacune jouant un rôle spécifique dans le système :
- Table "Groupes de Dépenses" : Cette table stocke des informations sur les différents groupes de dépenses créés par les utilisateurs. Chaque groupe est identifié par un nom unique et peut avoir une description pour une meilleure compréhension de son objectif.
- Table "Utilisateurs" : Cette table enregistre les profils des utilisateurs impliqués dans les groupes de dépenses. Chaque utilisateur est lié à un groupe spécifique, et son nom est enregistré pour une identification aisée.
- Table "Dépenses" : Les détails de chaque transaction financière sont stockés dans cette table. Chaque dépense est associée à un groupe particulier et enregistre son nom ainsi que le montant total.
- Tables "Contributeurs de Dépenses" et "Bénéficiaires de Dépenses" : Ces tables gèrent les relations entre les utilisateurs et les dépenses. Les contributeurs de chaque dépense sont enregistrés, ainsi que les bénéficiaires qui ont profité de cette dépense.
J'ai créé un fichier v0.sql dans un dossier migrations avec l'initialisation de mes tables.
Pour les mise à jour futures, plutôt que d'apporter des modifications directes à la base de données, les
migrations SQL cme permettront,à travers des scripts SQL, de décrire les modifications à apporter, telles que
l'ajout
de nouvelles tables, la modification des colonnes existantes ou la création d'index.
Ces scripts sont ensuite exécutés séquentiellement pour mettre à jour la structure de la base de données. Les
migrations SQL offrent une traçabilité complète des changements et permettent de revenir en arrière en cas de problème, garantissant ainsi la cohérence et
l'intégrité des données tout au long du cycle de vie d'une application.
L'Algorithme

Cette méthode qui appartient à la classe trigroupSQL a pour responsabilité de calculer les dettes total d'un groupe. L'algorithme utilise une fonction asynchrone pour intéragir avec la base de données MySQL et effectuer les calculs. On va décomposer chaque étapes clés et opérations de la méthode.
- Connexion à la BDD: On commence par établir une connexion à la base de données MySQL avec la configuration fournie dans la classe d'origine.
- Récuperer les dépenses: La méthode va ensuite chercher dans la base de donnée toutes les dépenses associées au groupe spécifié dans la requête.
- Calculé la dette: Pour chaque dépense, on récupère le contributeur et les
bénéficiaires, et on calcule le montant dû de chaque
bénéficiaire au contributeur. l'information est stocké dans un
tableau
debts. - Aplatir le tableau de dette: Le tableau
debtsqui était initialement un tableau de tableau, est aplati avec la methode.flat()pour en faire un tableau d'objets. - Déclaration de
userDebt: L'objet userDebts est créé pour stocket la dette de chaque utilisateur. Le tableau de dettes est itéré et la dette total de chaque utilisateur est calculé et mise à jour dans l'objet.userDebts - Conversion de
userDebtsen un tableau: L'objetuserDebtsva être converti en un tableau d'objetuserList, où chaque objet contient l'utilisateur et l'information sur sa dette respective. - Calculer les paiements: L'algorithme calcule une liste de paiement entre
utilisateurs. Il itère le tableau
userListet identifie des paires d'utilisateurs ou l'un doit de l'argentuser1.debt > 0et où l'autre est dûuser2.debt < 0. Le montant qui peut être transférer entre eux est calculé et les dettes sont mises à jour. - Résulats: La méthode retourne un objet qui contient 2 propriétés:
userDebtqui est une liste trié des utilisateurs et de leurs dette, ethowToBalancequi est une liste de paiements à faire entre utilisateurs pour annuler les dettes - Erreur et Cleanup: Chaque erreur qui survient pendant les opérations est attrapé
et affiché sur la console, et pour finir la connexion a la bdd
est coupé dans le bloc
finally
Cette section a offert un aperçu détaillé de la méthode de calcul des dettes totales d'un groupe, une composante essentielle de mon projet. Au cours de cette exploration, nous avons plongé dans les rouages de l'algorithme, mettant en lumière chacune de ses étapes clés et opérations.
Inversion de Dépendance
Au début de mon parcours de développement pour NoHasba, j'ai opté pour une solution simple mais limitée: stocker les données dans un fichier JSON et les manipuler en utilisant Node.js File System. Cela a permis un démarrage rapide du projet, mais rapidement, il est devenu évident que cette approche n'était pas évolutive ni maintenable à long terme.
Pour résoudre ces limitations, j'ai entrepris une refonte majeure de l'infrastructure de gestion des données en introduisant des concepts d'inversion de dépendance et de modularité. Voici comment cette transition s'est déroulée:
- Conception de l'Interface Trigroup: La première étape a consisté à créer une interface appelée "Trigroup". Cette interface a défini un ensemble de méthodes et de propriétés que toute classe de gestion de groupe de dépenses devrait implémenter. Cette abstraction a permis de définir un contrat clair pour la manipulation des données de groupe de dépenses.
- Implémentation de TrigroupJson et TrigroupSql: En utilisant l'interface "Trigroup" comme base, j'ai développé deux classes distinctes : "TrigroupJson" et "TrigroupSql". "TrigroupJson" est conçu pour gérer les données stockées dans des fichiers JSON, tandis que "TrigroupSql" est destiné à interagir avec une base de données SQL, offrant une flexibilité accrue pour le stockage des données.
- Mise en Place d'une Fabrique Abstraite: Une étape cruciale de cette transition a été la création d'une fabrique abstraite. Cette fabrique utilise une variable d'environnement pour déterminer quel type de gestionnaire de groupe de dépenses ("TrigroupJson" ou "TrigroupSql") doit être instancié. Cela a permis de rendre le choix du stockage des données flexible et adaptable en fonction des besoins du projet ou des préférences.
Ce changement d'approche a considérablement amélioré la maintenabilité de l'application et a ouvert la porte à des évolutions futures sans perturber le fonctionnement de base. En adoptant des principes d'inversion de dépendance et en créant une structure modulaire, NoHasba est devenu plus extensible, ce qui facilitera l'ajout de nouvelles fonctionnalités et le passage à d'autres systèmes de stockage de données si nécessaire.
Cette transition a également renforcé la qualité du code en séparant clairement les responsabilités et en permettant une meilleure gestion des erreurs, tout en préservant la cohérence et la stabilité du projet.